Vision encoder setting new standards in image & video tasks
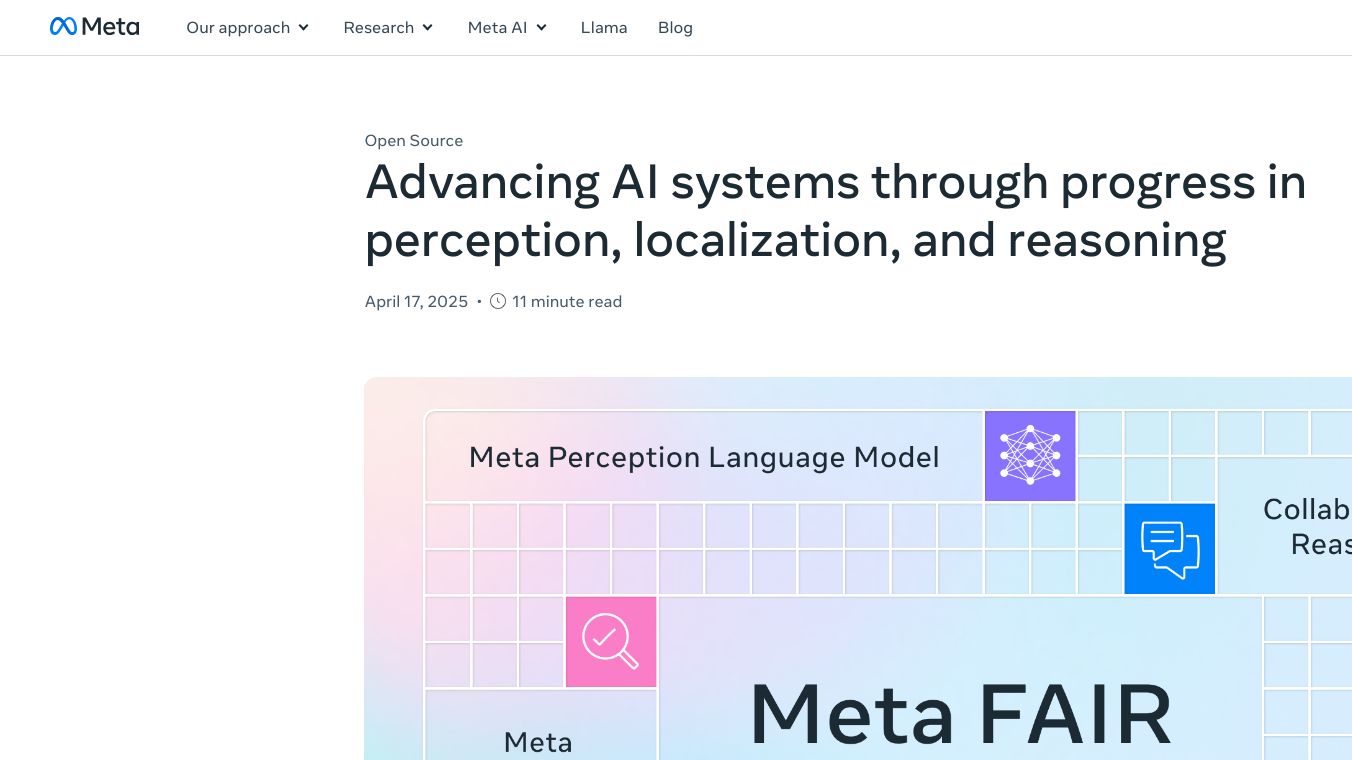
Meta''s Fundamental AI Research team has made a vision encoder. This tool is great for working with images and videos. It can handle many different tasks. This makes it very useful for many things.
Benefits
The vision encoder has many good points. It is trained to understand complex pictures and videos. This makes it very good at tasks that use both images and videos. It is also part of Meta''s open-source work. This means it is easy for anyone to use and share.
Use Cases
The vision encoder can be used in many real ways. It is great for helping machines see better. This is useful in things like self-driving cars, robots, and watching over places. It is also very helpful in healthcare. Doctors need to look at pictures and videos carefully. The vision encoder can help with this. It can also make other AI systems work better and more accurately.
Additional Information
Meta''s vision encoder is one of many AI tools made by the Fundamental AI Research team. Other tools include the Perception Language Model, Locate-3D, Byte-Level Transformer, Segment Anything Model 2.1, Meta Spirit LM, Layer Skip, Salsa, Meta Lingua, Meta Open Materials 2024, Mexma, and Video Joint Embedding Predictive Architecture. Each of these tools helps with different AI problems. Some help with seeing in 3D, others help with talking. Meta wants these tools to be easy to use and share. This helps others make new things in AI.


Comments
Please log in to post a comment.