SelfHostLLM
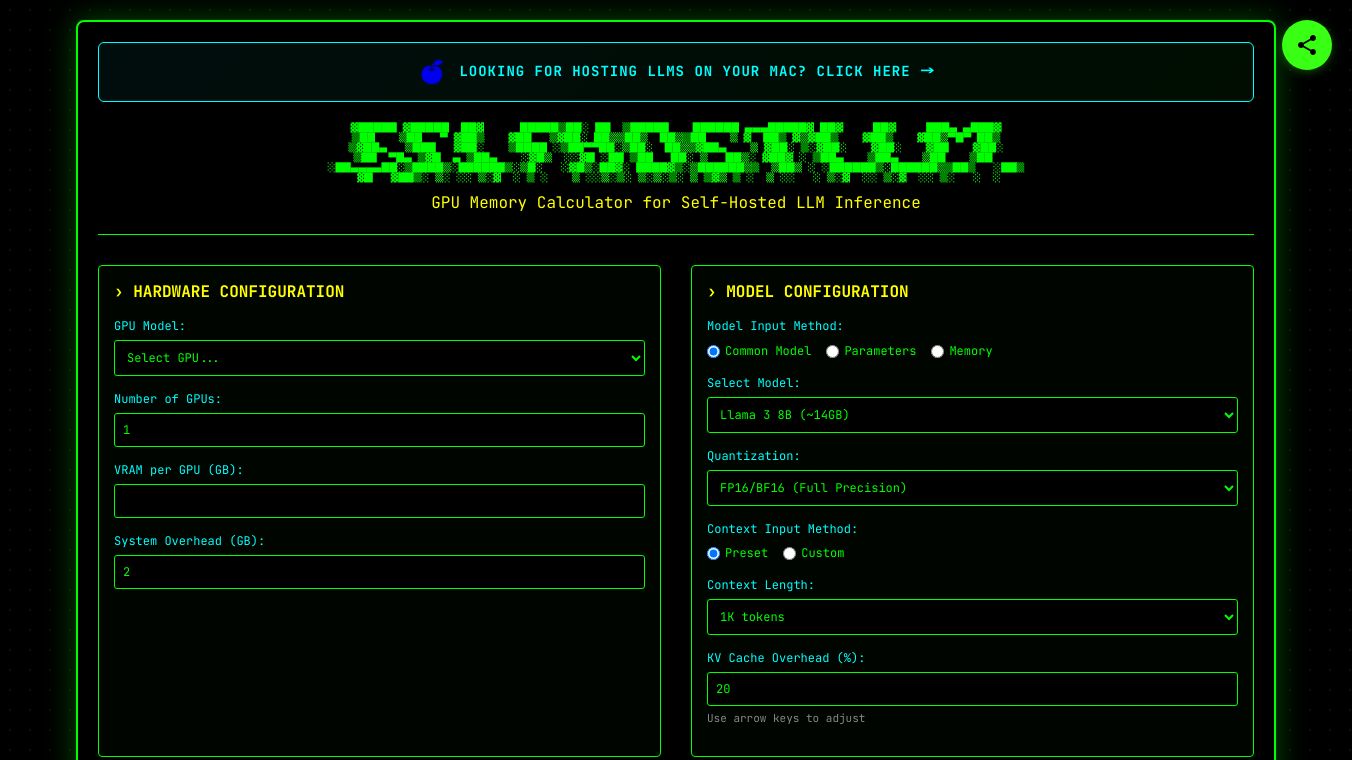
What is SelfHostLLM?
SelfHostLLM is a tool designed to help users estimate the performance of self-hosted large language models (LLMs). It provides calculations for how many concurrent requests a GPU can handle and estimates the speed of token generation. This tool is particularly useful for individuals or organizations looking to deploy LLMs on their own hardware, ensuring they have the right setup for their needs.
Benefits
SelfHostLLM offers several key advantages:
- Performance Estimation:Helps users understand how many concurrent requests their GPU can handle, ensuring efficient use of hardware.
- Speed Prediction:Estimates the speed of token generation, allowing users to gauge the responsiveness of their LLM setup.
- Customizable Configurations:Users can input specific details about their hardware and model to get tailored results.
- Educational Insights:Provides explanations of how different factors like quantization, context length, and GPU memory affect performance.
Use Cases
SelfHostLLM is useful in various scenarios:
- Personal Use:Individuals looking to run LLMs on their personal computers can use SelfHostLLM to ensure their hardware is sufficient.
- Small-Scale Deployment:Small businesses or research groups can use the tool to plan their LLM deployments effectively.
- Production Environments:Organizations deploying LLMs in production can use SelfHostLLM to optimize their hardware setup for maximum efficiency.
Additional Information
SelfHostLLM considers various factors in its calculations, including:
- GPU Memory Bandwidth:Higher bandwidth GPUs can handle more concurrent requests and generate tokens faster.
- Model Size Efficiency:Smaller models achieve better utilization of memory bandwidth.
- Quantization Speed Boost:Lower precision allows faster computation and memory access.
- Context Length Impact:Longer contexts require more memory operations, affecting performance.
- Multi-GPU Scaling:Multiple GPUs can improve performance, though not perfectly due to communication overhead.
By providing detailed insights into these factors, SelfHostLLM helps users make informed decisions about their LLM deployments.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.
Comments
Please log in to post a comment.