PoplarML
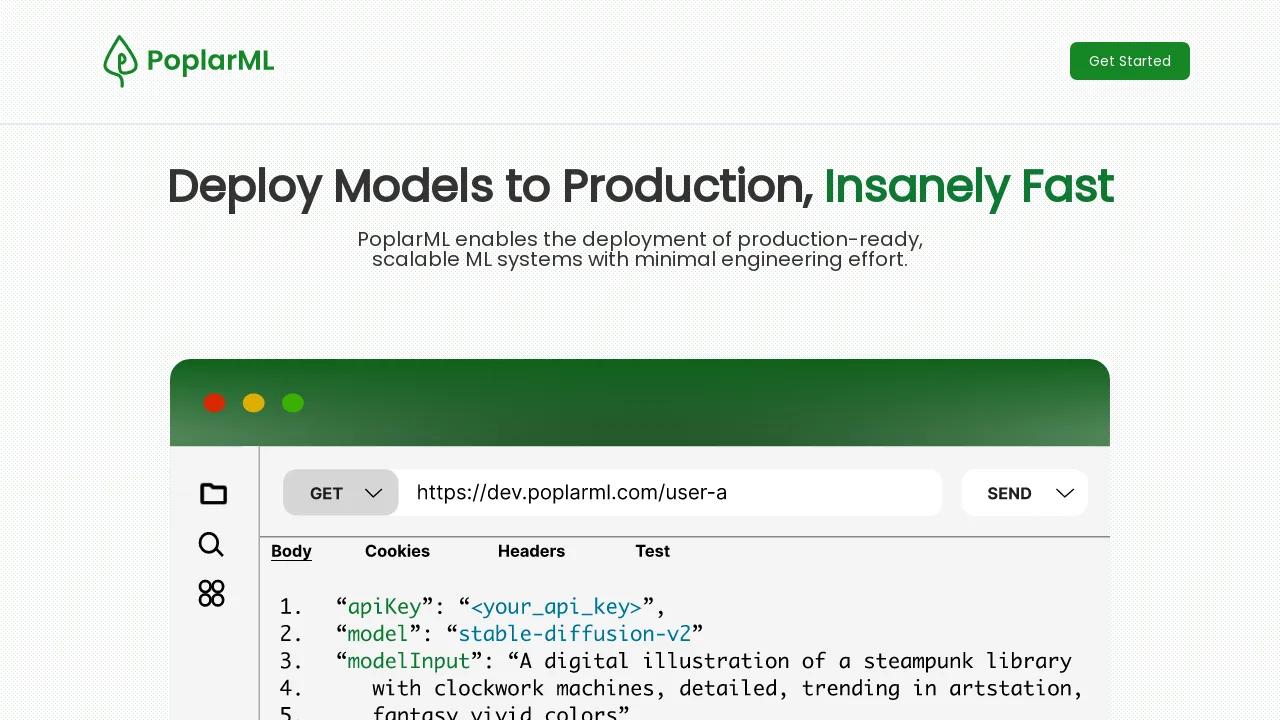
PoplarML is a game-changer for anyone wanting to deploy powerful machine learning models without the hassle. It simplifies the process, allowing you to seamlessly deploy models onto a fleet of GPUs with just a few clicks. Need real-time predictions? PoplarML lets you access your models through a REST API endpoint, making it easy to integrate into your existing applications. Whether you use TensorFlow, PyTorch, or JAX, PoplarML is framework-agnostic, ensuring flexibility and compatibility with your chosen tools.
Highlights
- One-Click Deploys: Deploy your ML models effortlessly with a simple CLI tool, scaling to a fleet of GPUs.
- Real-Time Inference: Get instant predictions from your models using a REST API endpoint.
- Framework Agnostic: Work with TensorFlow, PyTorch, or JAX – PoplarML supports them all.
Key Features
- Seamless Deployment: Simplified deployment process for production-ready ML systems.
- Scalability: Deploy models to a fleet of GPUs for high-performance processing.
- REST API: Access models for real-time inference through a convenient API.
- Framework Compatibility: Support for popular ML frameworks, including TensorFlow, PyTorch, and JAX.

Comments
Please log in to post a comment.