Nemotron
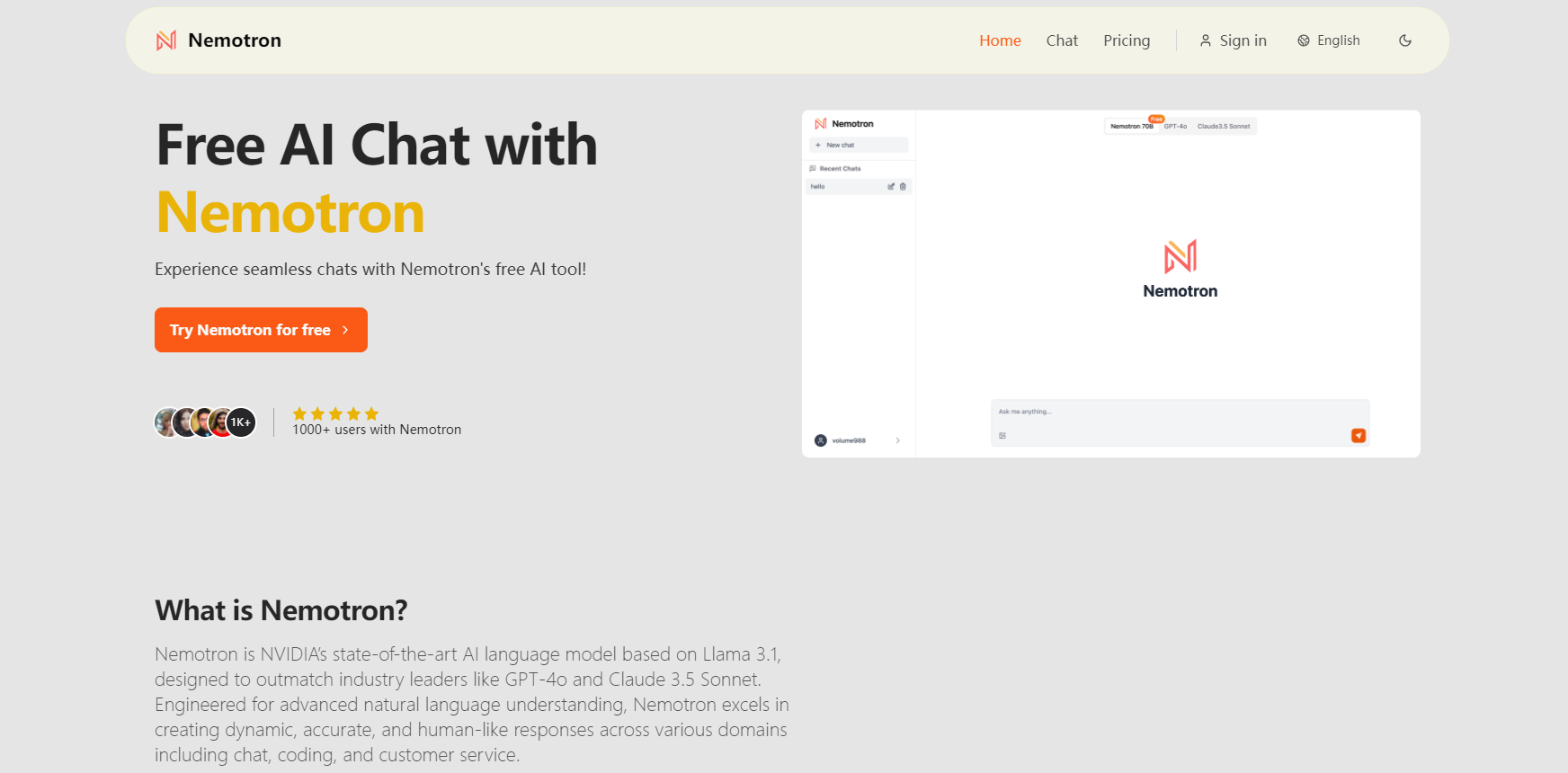
Nemotron represents NVIDIA's advanced suite of language models, with variants ranging from the powerful 340B-parameter model to smaller, efficient versions like the 4B model. The family includes base, instruct, and reward models, all released under the NVIDIA Open Model License for commercial use. These models are built on advanced architectures and trained on diverse datasets spanning 50+ natural languages and 40+ coding languages, making them versatile tools for various AI applications. Notable members include the Llama-3.1-Nemotron-70B-Instruct, which has demonstrated superior performance compared to leading models like GPT-4 and Claude 3.5.
Nemotron is NVIDIA's advanced language model family based on Llama architecture, featuring models ranging from 4B to 340B parameters. It's designed to deliver superior performance in natural language understanding and generation through RLHF training and instruction tuning. The flagship Llama 3.1 Nemotron 70B model outperforms competitors like GPT-4o in benchmarks, offering enhanced capabilities for enterprise applications while supporting extensive context lengths and maintaining high accuracy.
Highlights:
- Superior performance compared to leading models like GPT-4 and Claude 3.5
- Extensive language and coding language support
- Enterprise-ready integration with NVIDIA NeMo Framework and Triton Inference server
- Versatile model variants from 4B to 340B parameters
- Advanced customization capabilities for specific use cases
Key Features:
- Advanced architecture with multi-head attention and optimized design
- Supports Parameter-Efficient Fine-Tuning (PEFT), prompt learning, and RLHF
- Compatible with NVIDIA NeMo Framework and Triton Inference server
- Multiple model variants including base, instruct, and reward models
- Supports context lengths up to 128k tokens
Benefits:
- Enhanced natural language understanding and generation
- Optimized deployment options and TensorRT-LLM acceleration
- Flexible customization for specific use cases
- Robust support for enterprise applications
- High accuracy and extensive context lengths
Use Cases:
- Synthetic data generation for various domains
- Powering virtual assistants and customer service bots
- Assisting in coding tasks and problem-solving
- Supporting academic and scientific research
- Enhancing enterprise AI applications
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.






Comments
Please log in to post a comment.