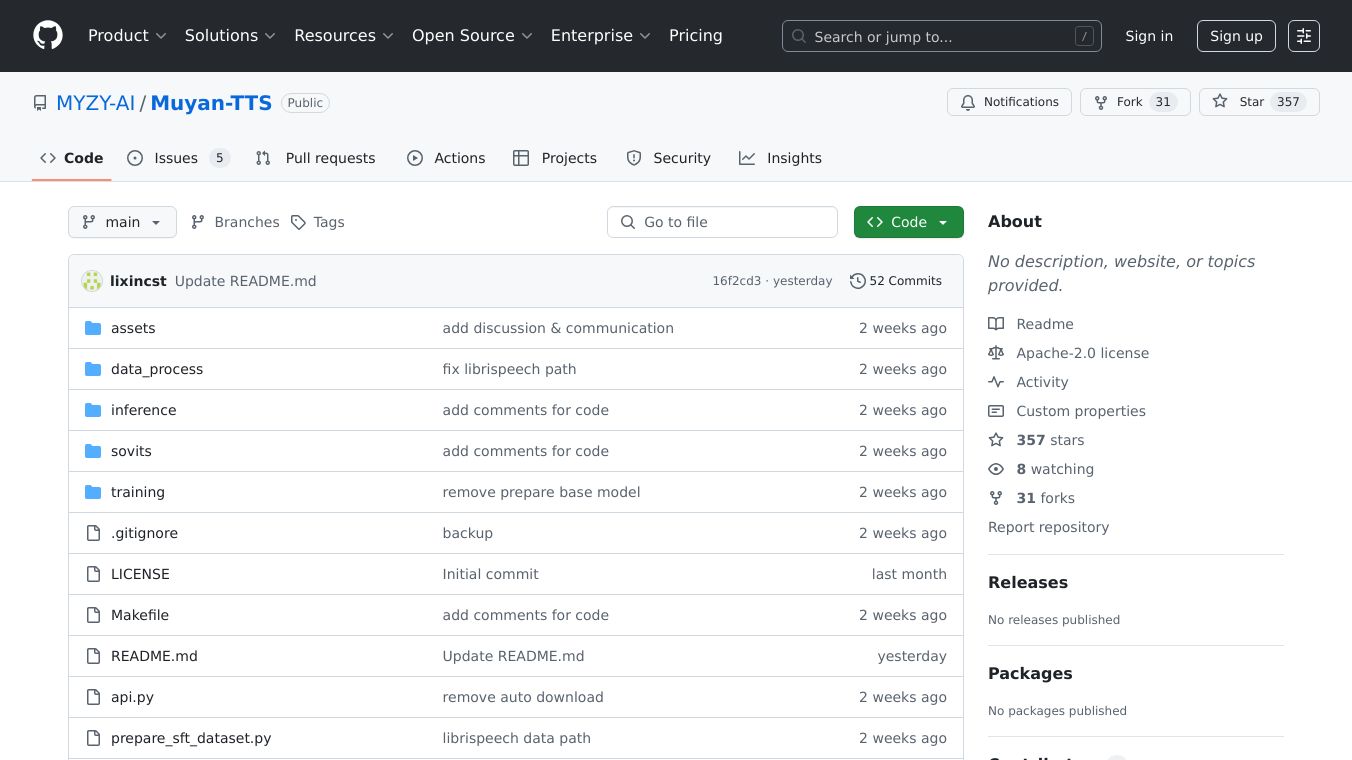
Muyan-TTS
You are a content rewriter. Your job is to make AI text sound more human and easy to understand. You will rewrite the provided AI content to make it sound like a friendly human wrote it. The rewritten content should be in simple English. A 9th grader should be able to understand it. You must only use the information provided in the article. Do not include any extra information. You must keep the context and meaning of the original AI content as close as possible. Do not change the format or the structure of the article.
Muyan-TTS is an open-source, trainable text-to-speech model. It is made for podcast applications. It is pre-trained on over 100,000 hours of podcast audio data. This allows for high-quality voice generation and zero-shot TTS synthesis. The model supports speaker adaptation with just a few minutes of target speech. This makes it highly customizable for individual voices. Muyan-TTS is built within a $50,000 budget. This ensures accessibility and affordability for developers and researchers.
Benefits
Muyan-TTS offers several key advantages. It can generate high-quality speech without requiring extensive fine-tuning. This makes it ideal for quick deployment in various applications. The model can be fine-tuned with a few minutes of a target speaker''s voice. This allows for personalized voice cloning and customization. It is also highly efficient. It generates one second of audio in approximately 0.33 seconds. This makes it one of the fastest TTS models available. Being open-source, it provides full access to model weights, training scripts, and data workflows. This enables easy retraining and adaptation.
Use Cases
Muyan-TTS is suitable for a wide range of applications. It can be used for podcast creation, audiobook production, English video dubbing, AI character narration, and smart speaker announcements. Its efficiency and adaptability make it an ideal choice for developers and researchers. They can integrate high-quality TTS into their projects.
Additional Information
Muyan-TTS integrates a pre-trained large language model with a VITS-based decoder. The large language model is based on Llama-3.2-3B. It is fine-tuned on a parallel corpus of text and audio tokens. The VITS-based decoder is optimized for podcast scenarios. This ensures high-quality and natural-sounding speech. The data processing pipeline involves several stages. These include data collection, cleaning, and formatting. This enhances clarity and intelligibility. The training process includes pre-training of the large language model, supervised fine-tuning, and decoder training. This optimizes for podcast scenarios. Muyan-TTS has been benchmarked against popular open-source models. It demonstrates competitive performance in terms of Word Error Rate, Mean Opinion Score, and Speaker Similarity Index.



Comments
Please log in to post a comment.