DocumentLLM
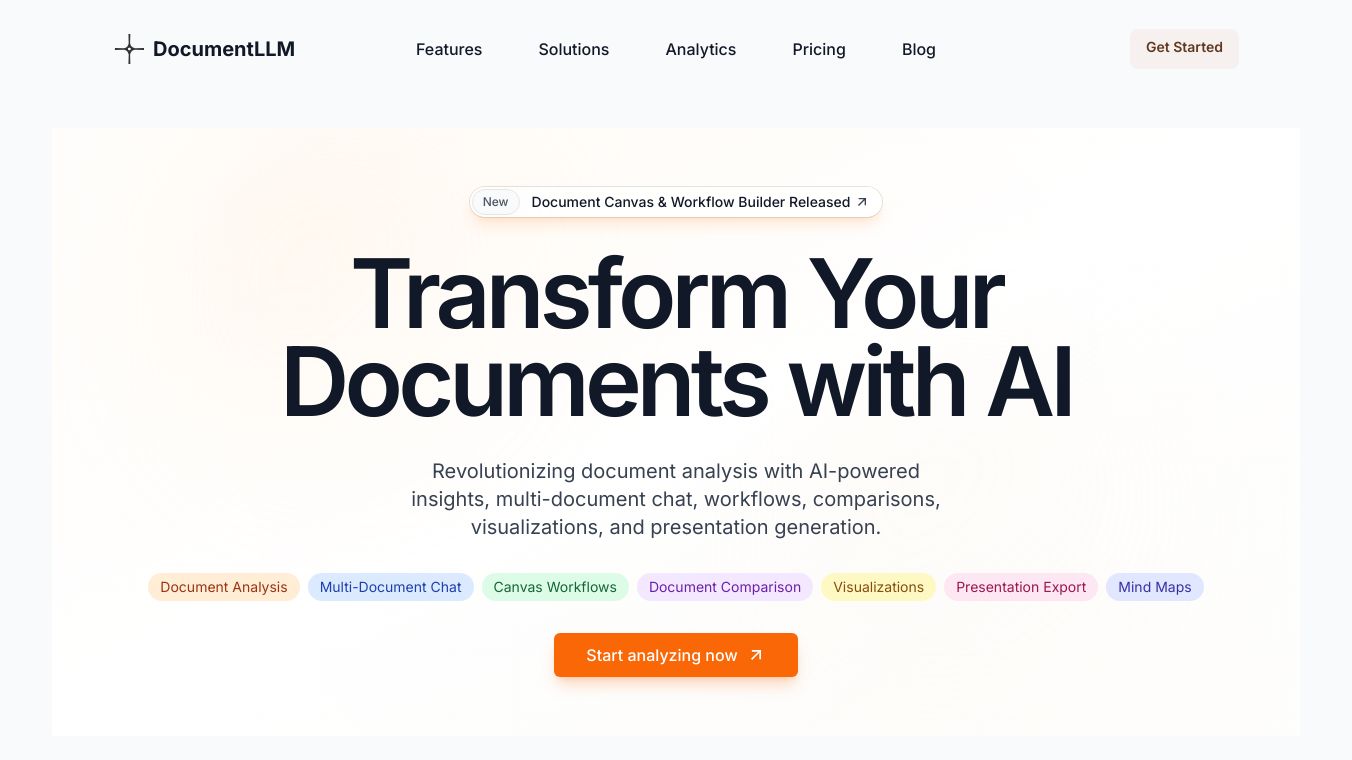
DocLLM, created by JPMorgan, is a clever tool that understands and handles documents with lots of visual content like forms, invoices, receipts, and reports. It uses both text and layout information to make sense of these documents, which sets it apart from traditional methods.
Key Features
DocLLM has several key features that make it unique.
It can handle documents with both text and visual layouts, making it versatile for different types of content.
The model understands the arrangement and positioning of text elements within a document, capturing the geometry and layout of the content.
This feature helps the model understand complex document structures by computing separate attention scores for text and spatial information.
DocLLM learns to fill in missing text segments, making it adaptable to varied layouts and diverse content.
This allows each element in a sequence to attend to other elements, capturing long range dependencies.
This process generates or predicts masked or missing text segments based on the surrounding context.
DocLLM is fine tuned on a dataset of instructions, prompts, and expected outputs, enabling it to follow instructions for various tasks.
These are rectangular regions that enclose text elements, capturing their spatial positioning and layout geometry.
Benefits
DocLLM offers several benefits.
It handles documents with varied layouts and diverse content more efficiently than traditional methods.
The model can adapt to tasks involving visually complex documents, making it useful for a wide range of applications.
DocLLM outperforms other language models like GPT 4 and Llama2 in understanding and analyzing documents with lightweight visual elements.
Use Cases
DocLLM can be used in various scenarios.
It can extract information from forms accurately.
The model can answer questions based on document content.
It can classify the type of document effectively.
Cost or Price
The cost or price of DocLLM is not provided in the article.
Funding
The funding details of DocLLM are not provided in the article.
Reviews or Testimonials
DocLLM was evaluated on 16 datasets across four tasks in two experimental settings. It outperformed equivalent LLM baselines on 14 out of 16 SDDS settings and 4 out of 5 STDD settings. Users have found it particularly effective in layout intensive tasks like key information extraction and document classification.


Comments
Please log in to post a comment.